x-technology

Building a RAG System in Node.js: Vector Databases, Embeddings & Chunking
Large Language Models (LLMs) are powerful, but they often lack real-time knowledge. Retrieval-Augmented Generation (RAG) bridges this gap by fetching relevant information from external sources before generating responses. In this workshop, we’ll explore how to build an efficient RAG pipeline in Node.js using RSS feeds as a data source. We’ll compare different vector databases (FAISS, pgvector, Elasticsearch), embedding methods, and testing strategies. We’ll also cover the crucial role of chunking—splitting and structuring data effectively for better retrieval performance.
Prerequisites
- Good understanding of JavaScript or TypeScript
- Experience with Node.js and API development
- Basic knowledge of databases and LLMs is helpful but not required
Code
Agenda
- Introduction 📢
- About Everything 🌎
- Setup 🛠️
- Demo #1 - Hello World 👋
- Use Case - Exploring Node.js News 📰
- Chunking ✂️
- Demo #2 - Chunking 🧩
- Store & Retrieve 🗂️
- Demo #3 - Store & Retrieve 🔍
- Reranking 🥇
- Evaluation 📊
- Demo #4 - Evaluation 🧪
- MCP World 🌎
- Demo #5 - MCP ⛵️
- Summary 📚
- Feedback 💬
- Links 🔗
Introduction
- Explore RAG’s scope, architecture and components
- Demo various RAG aspects with chosen technologies
- Feedback & evaluate
Alex Korzhikov

Software Engineer, Netherlands
My primary interest is self development and craftsmanship. I enjoy exploring technologies, coding open source and enterprise projects, teaching, speaking and writing about programming - JavaScript, Node.js, TypeScript, Go, Java, Docker, Kubernetes, JSON Schema, DevOps, Web Components, Algorithms 🎧 ⚽️ 💻 👋 ☕️ 🌊 🎾
Pavlik Kiselev

Software Engineer, Netherlands
JavaScript developer with full-stack experience and frontend passion. He happily works at ING in a Fraud Prevention department, where helps to protect the finances of the ING customers.
About Everything
Generative Artificial Intelligence (GenAI)
Use of Artificial Intelligence to produce human consumable content in text, image, audio, video format.
Language Model (LM)
Language Models are Machine Learning models trained on natural language resources and aim predict next word based on given context.
LM relevant tasks - summarization, Q&A, classification, and more.
Large Language Model (LLM)
Artificial Intelligence is powered by Large Language Models - models trained on tons of sources and materials, having billions of parameters.
Retrieval Augmented Generation (RAG)
RAG is a method that combines information retrieval with language model generation.
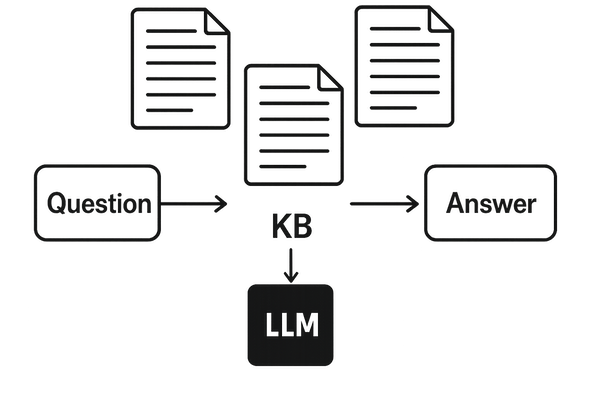
Indexing = Offline
Retrieval = Search
Generation = LLM
Use Cases:
- Chat with user
- Analyze and summarise documents
async function rag(q) {
const results = await search(q)
const prompt = makePrompt(q, results)
const answer = await llm(prompt)
return answer
}
Why do we need RAG?
- Additional, specific knowledge- Reduce hallucinations
- Control system costs
Why can't we just put all context in our LLM and ask it about?
- Cost- Slow
- Size
- Noize
What do we need to build a RAG?
- Application (backend)- Search system (vector databases)
- LLM (blackbox)
Langchain 🦜️🔗
LangChain is a Python and JavaScript framework that brings flexible abstractions and AI-first toolkit for developers to build with GenAI and integrate your applications with LLMs. It includes components for abstracting and chaining LLM prompts, configure and use vector databases (for semantic search), document loaders and splitters (to analyze documents and learn from them), output parsers, and more.
Setup
- Node.js
- Ollama / OpenAI
npm i langchain
Demo #1 - Hello World
ollama.chat({
messages: [
{ role: "user", content: "What is retrieval-augmented generation?" },
],
});
Use Case - Exploring Node.js News
We aim to understand what happened in the Node.js community over the past year. To achieve this, we:
- Collect and process news, popular blog posts, and articles
- Store the documents in a database
- Analyze and query the documents by asking targeted questions
How do we find sources?
- Own collection
- Ask ChatGPT What are the best online resource to follow on Node.js news? Output urls and short description
How do we scrap articles?
- Direct fetch requests
- Run browser and navigate to urls
- Use external services
Some scrapping and text quality problems
- Paywalls
- Anti-bot protections
- Cat & mouse game
- Noise (marketing texts, tags, js, css)
- Clean & parse
- Noise reduction algorithms
Articles
- What dataset do you have?
- Which format do you need to parse?
- What are the most often queries?
Chunking
To chunk or not to chunk?
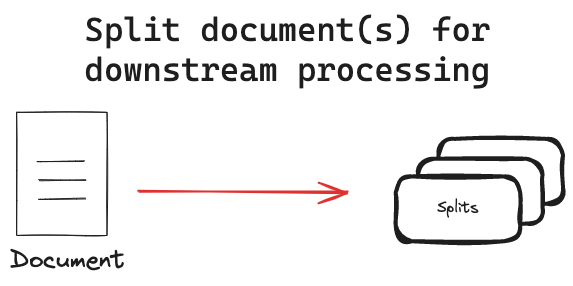
Chunking involves breaking down texts into smaller, manageable pieces called “chunks”. Each chunk becomes a unit of information that is vectorized and stored in a database, fundamentally shaping the efficiency and effectiveness of natural language processing tasks.
- Normalize documents
- Reduce context (latency, LLM usage & cost)
- Enhance retrieval precision
How do we split documents?
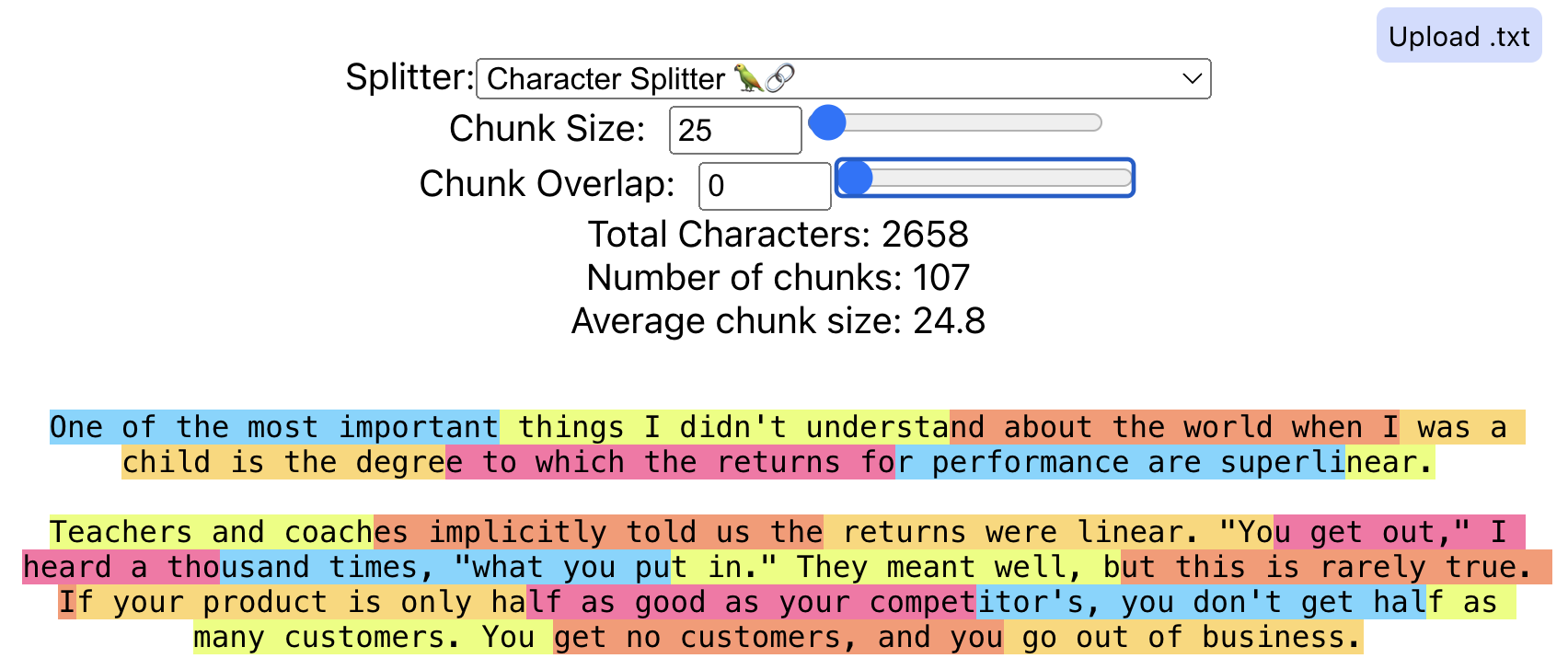
- Chunk Size
The number of characters we would like in our chunks. 50, 100, 100,000, etc.
- Chunk Overlap
The amount we would like our sequential chunks to overlap. This is to try to avoid cutting a single piece of context into multiple pieces. This will create duplicate data across chunks.
-
Length-based (
CharacterTextSplitter) - Easy & Simple, don’t take into account the text’s structure - Character/Token splitters
const { CharacterTextSplitter } = require("@langchain/textsplitters")
const textSplitter = new CharacterTextSplitter({
chunkSize: 100,
chunkOverlap: 0,
})
const texts = await textSplitter.splitText(document)
-
Text-structured based (
RecursiveCharacterTextSplitter) -
What split characters do you think are included in Langchain by default?
-
Semantic meaning based - Extract Propositions
-
Agentic Chunking
- Summarize text, propositions, images
- Generate hypothetical questions
- Multiple embeddings
Demo #2 - Chunking
const { RecursiveCharacterTextSplitter } = require("@langchain/textsplitters");
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 100,
chunkOverlap: 0,
});
return await splitter.splitText(text);
Store & Retrieve

- Semantic VS Keyword Search
To embed or not?
An embedding is a vector representation of data in embedding space (projecting the high-dimensional space of initial data vectors into a lower-dimensional space).
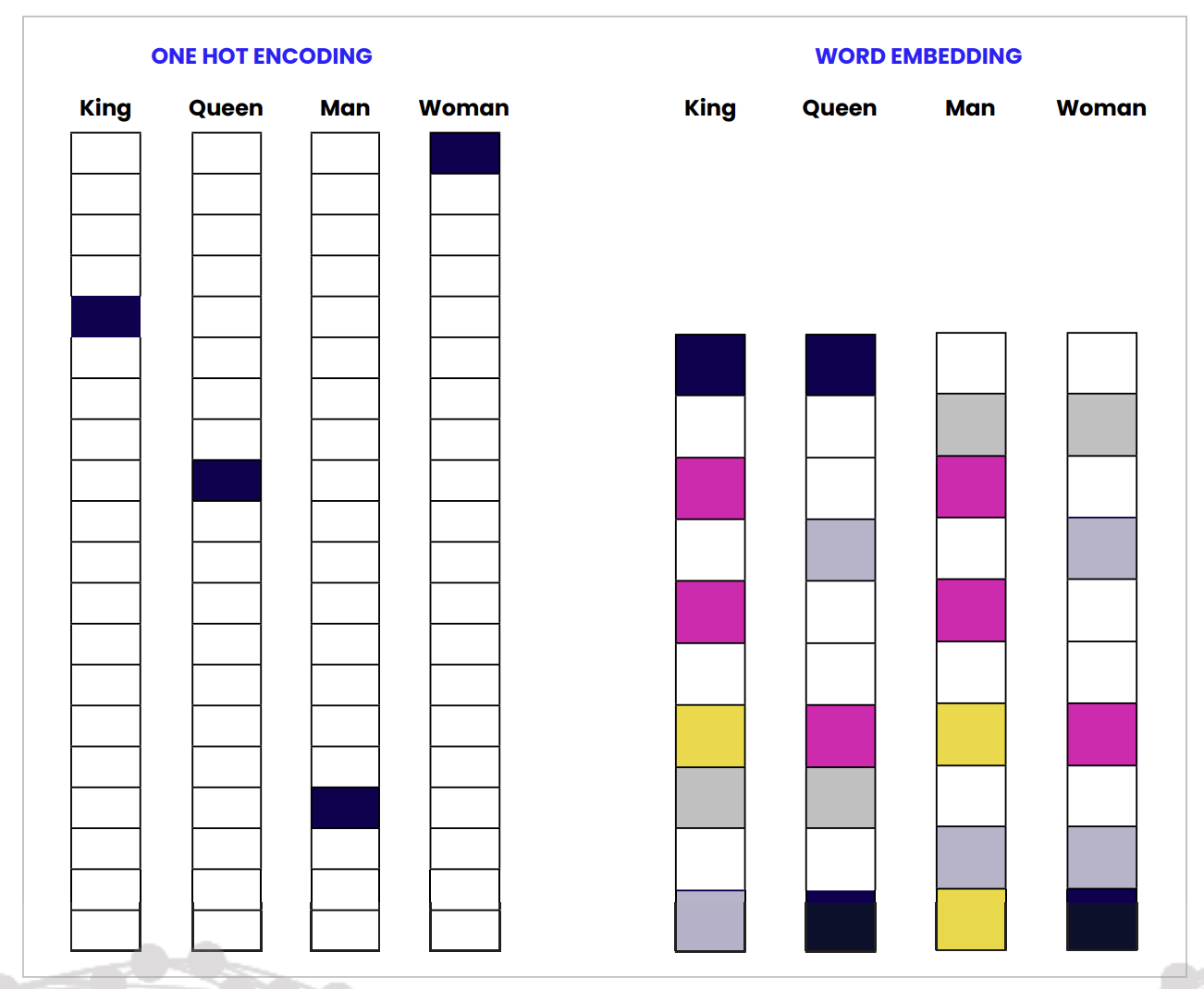
Vectors are stored in a database, which compare them as a way to search for data that is similar in meaning (by using dot product or cosine measurement).

Can we exchange embedding models with equal vector dimensions?
- Nope, also embedding models evolve over time
Demo #3 - Store & Retrieve
await Chroma.fromTexts(
texts,
{ id: Array.from({ length: texts.length }, (_, i) => `chunk-${i}`) },
embeddings,
{ collectionName: "rag_node_workshop_articles" },
);
Reranking
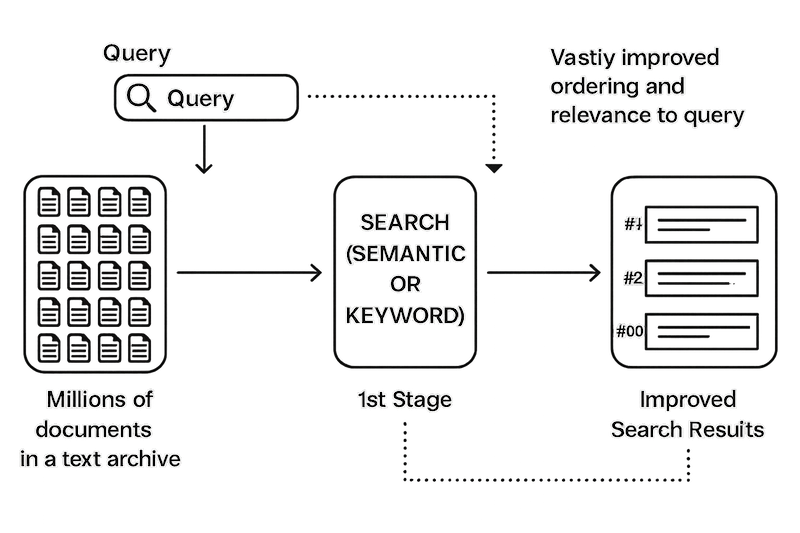
Rerankers analyze the initial search output and adjust the ranking to better match user preferences and application requirements
- Improve quality (other models and more context involved)
- Cost considerations
- Vector VS LLM based
Evaluation

Evaluate RAG the retriever and generator of a RAG pipeline separately
Retriever
Hyperparameters:
- Database
- Embedding model
- Chunk size
- Top-K documents
- LLM temperature
- Prompt template
- Reranking model
- etc.
Does your reranker model ranks the retrieved documents in the “correct” order?
Metrics:
- Precision - whether documents in the retrieved context that are relevant to the given input are ranked higher than irrelevant ones
- Recall - how well the retrieved context aligns with the expected output, or if all relevant documents are retrieved
Generation
Hyperparameters:
- Prompt template
- LLM
Can we use a smaller, faster, cheaper LLM?
Metrics:
- Faithfulness / Groundedness - whether the actual output factually aligns with the retrieved context
- Answer relevancy - how relevant the actual output is to the provided input
Frameworks
Our choice
-
Hit Rate (HR) or Recall at k: Measures the proportion of queries for which at least one relevant document is retrieved in the top k results.
-
Mean Reciprocal Rank (MRR): Evaluates the rank position of the first relevant document.
-
Chunk attributions/utilization - if chunk contributed to model/rag response
- What low numbers might show us?
- How do we define numbers?
Demo #4 - Evaluation
const relevantDocs = await getRelevantDocuments(vectorStore, summary);
const relevance = relevantDocs.map((d) => d.pageContent === chunk);
console.log(hitRate(relevance));
MCP World
- AI agents

AI agents are AI programs built on top of LLMs. They use LLM information-processing capabilities to obtain data, make decisions, and take actions on behalf of human users.
-
Agents vs Workflows
-
Agent Protocols
Agent protocols are standardized frameworks that define the rules, formats, and procedures for structured communication among agents and between agents and external systems
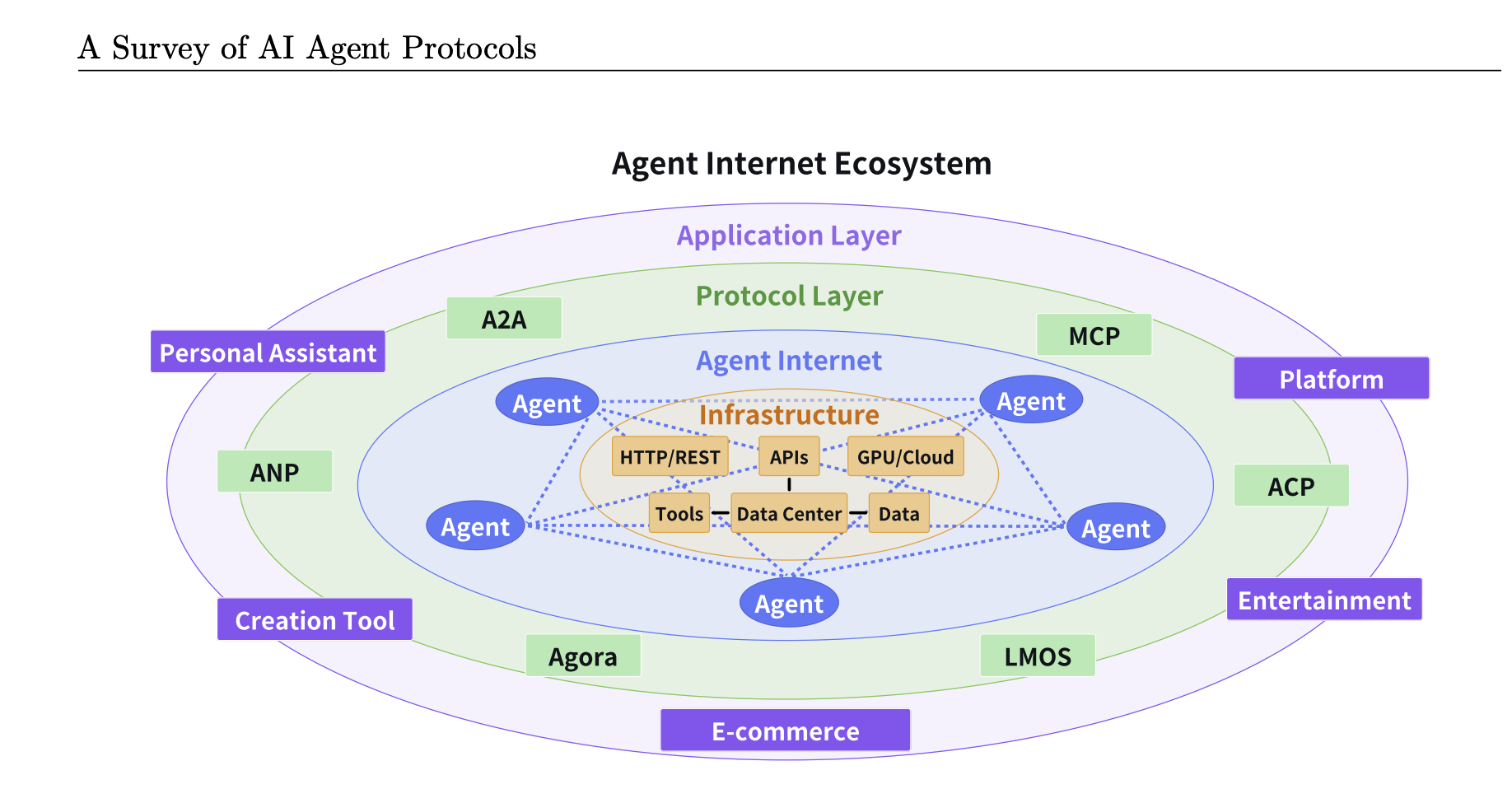
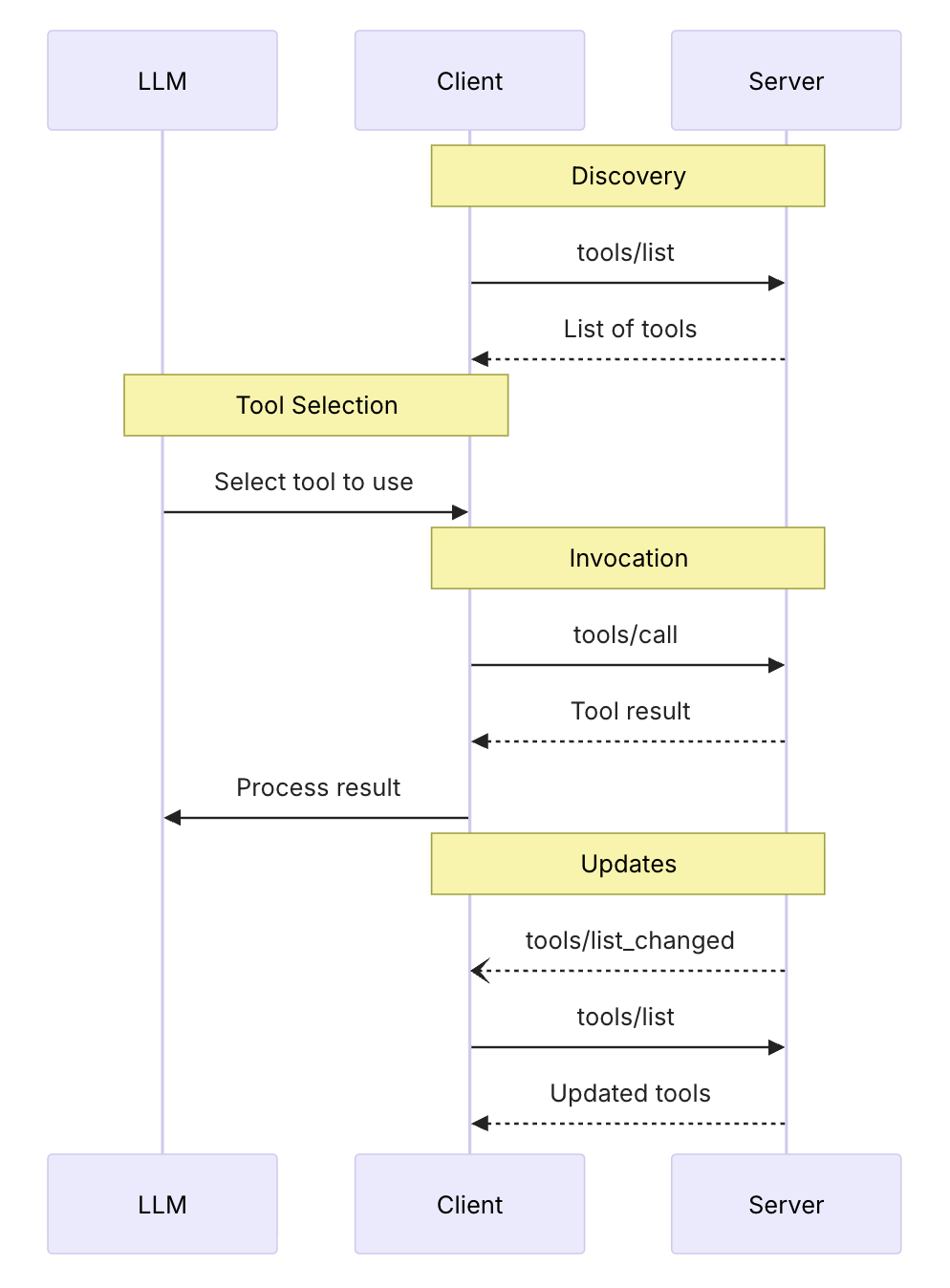
- MCP - Model Context Protocol
Anthropic, November 2024, Specification
MCP provides a standardized way for applications to:
- Share contextual information with language models
- Expose tools and capabilities to AI systems
- Build composable integrations and workflows
based on the Function calling flow
for (const toolCall of response.output) {
if (toolCall.type !== "function_call") {
continue
}
const name = toolCall.name
const args = JSON.parse(toolCall.arguments)
const result = callFunction(name, args)
input.push({
type: "function_call_output",
call_id: toolCall.call_id,
output: result.toString(),
})
}
- Resources: Context and data, for the user or the AI model to use
- Prompts: Templated messages and workflows for users
- Tools: Functions for the AI model to execute
- Communication Layer: Authentication, Notifications, JSON-RPC
- Servers
{
"name": "get_weather_data",
"title": "Weather Data Retriever",
"description": "Get current weather data for a location",
"inputSchema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name or zip code"
}
},
"required": ["location"]
},
"outputSchema": {
"type": "object",
"properties": {
"temperature": {
"type": "number",
"description": "Temperature in celsius"
},
"conditions": {
"type": "string",
"description": "Weather conditions description"
},
"humidity": {
"type": "number",
"description": "Humidity percentage"
}
},
"required": ["temperature", "conditions", "humidity"]
}
}
- SDK
- Server
npx -y tsx 4-mcp.ts
- vscode github copilot
- vscode openai codex
// vscode settings.json
"my-server": {
"type": "http",
"url": "http://localhost:3000/mcp"
}
# codex config
[mcp_servers.my-server]
url = "http://localhost:3000/mcp"
- MCP inspector
npx @modelcontextprotocol/inspector
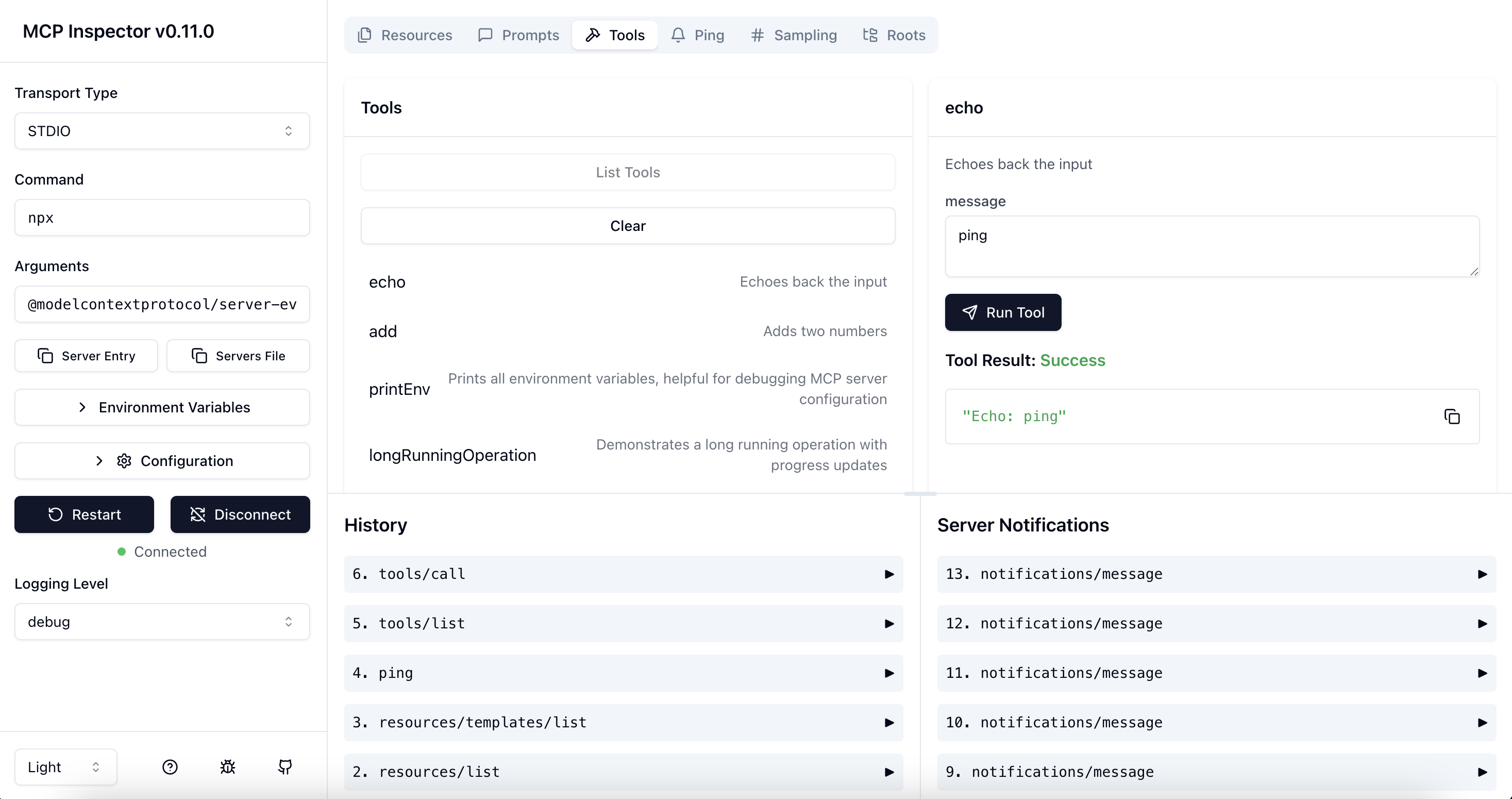
- What are components in the agent of our system?
- What can you do with MCPs locally?
Demo #5 - MCP
const client = new Client({
name: "rag-workshop-mcp-client",
version: "1.0.0",
})
// Call a tool
const result = await client.callTool({
name: "get_documents",
arguments: {
q: "What's terraform used for?",
},
})
Summary
The workshop overviews and samples RAG system architecture in Node.js, connecting data ingestion, embedding, and retrieval layers into a unified pipeline. It explores how the RAG pattern enhances LLMs with external knowledge, improving accuracy and adaptability in real-world applications.
Feedback
Please share your feedback on the workshop. Thank you and have a great coding!
If you like the workshop, you can become our patron, yay! 🙏
Links
- Mete Atamel - A blog about software development and more
- Build a Retrieval Augmented Generation (RAG) App
- 5 Levels Of Text Splitting
- LlamaIndex - End-to-end tooling to ship a context-augmented AI agent to production
- Ragas - Ultimate toolkit for evaluating and optimizing Large Language Model (LLM) applications.
- deepeval - the open-source LLM evaluation framework
- LLM Zoomcamp - A Free Course on Real-Life Applications of LLMs
- Machine Learning Crash Course
- DeepEval - RAG Evaluation
- Cohere - Say Goodbye to Irrelevant Search Results: Cohere Rerank Is Here
- 5-Day Gen AI Intensive Course with Google Learn Guide
- MCP: Build Rich-Context AI Apps with Anthropic
- A Survey of AI Agent Protocols
- Lilian Weng - LLM Powered Autonomous Agents
Technologies
- LLM
- Langchain
- RAG
- AI Agents
- MCP